Worldwide Pose Estimation using 3D Point Clouds
| Yunpeng Li | Noah Snavely | Dan Huttenlocher | Pascal Fua |
Abstract
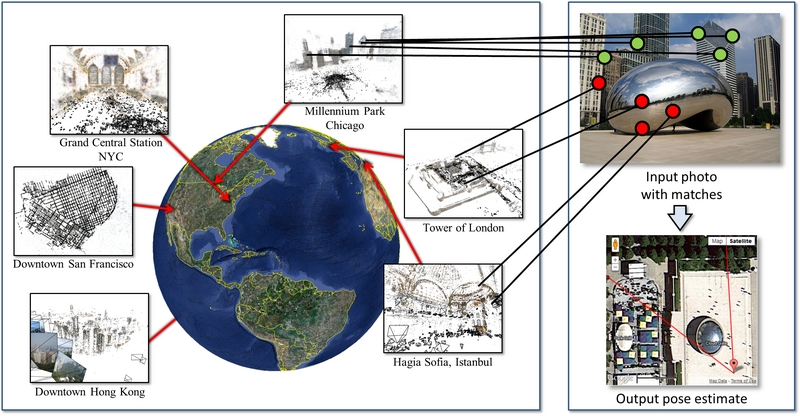
We address the problem of determining where a photo was taken by estimating a full 6-DOF-plus-intrincs camera pose with respect to a large geo-registered 3D point cloud, bringing together research on image localization, landmark recognition, and 3D pose estimation. Our method scales to datasets with hundreds of thousands of images and tens of millions of 3D points through the use of two new techniques: a co-occurrence prior for RANSAC and bidirectional matching of image features with 3D points. We evaluate our method on several large data sets, and show state-of-the-art results on landmark recognition as well as the ability to locate cameras to within meters, requiring only seconds per query.
Paper - ECCV 2012
| Paper (PDF, 2.0MB) | ||||
| Supplemental material (PDF, 5.1MB) | ||||
| Poster (PDF, 10.1MB) | ||||
| Video demo (AVI, 2.1MB) | ||||
Bibtex: @InProceedings{ li:eccv:2012,
author = {Yunpeng Li and Noah Snavely and Daniel Huttenlocher and
Pascal Fua},
title = {Worldwide Pose Estimation using 3{D} Point Clouds},
booktitle = European Conf. on Computer Vision,
year = 2012
}
| ||||
Datasets
We provide two datasets from the paper below, Landmark10k and San Francisco. If you use either dataset, please cite our ECCV 2012 paper above.
|
Landmarks10k Data file (~5.x GB tar.gz), README file Bundler-style Structure from Motion models computed for images from 10,000 major world landmarks. The models are in a georeferenced coordinate system. We are unable to include the original images, although the image sources are documented. Visualizations of these datasets can be found at the Landmarks10K page. |
|
San
Francisco Structure from Motion model of much of downtown San Francisco created from the 1.7-million-image San Francisco Landmark Dataset of Chen et al. There are two versions of this dataset, as described in the paper: SF-0 is created using original images and standard SIFT, whereas SF-1 is created using histogram-equalized images and upright SIFT (yielding a larger number of reconstructed images). This release consists of several files (thanks to Torsten Sattler for archiving this data!):
Sattler, Torii,
Sivic, Pollefeys, Taira, Okutomi,
Pajdla |
See also
| Location Recognition using Prioritized Feature Matching |
Acknowledgements
This work was supported in part by the NSF (grants IIS-0713185 and IIS-1111534), Intel Corporation, Amazon.com, Inc., MIT Lincoln Laboratory, and the Swiss National Science Foundation. We also thank Flickr users for use of their photos.